注:其实自认为还是非常喜欢数学的,但是对于复杂的公式还是有种恐惧感,就像最开始学英语时,对英语的感觉一样。但是数学与英语不同的地方在于,你可以尽情的刨根问底,从最基础的知识开始了解,直到最终把一个符号或者公式的含义弄明白。在机器学习的过程中,也会碰到各种各样的符号,尤其是遇到多参数,多样本的情况时,更是让人眼花缭乱。最近学习完coursera上吴恩达老师的机器学习前两周的课程,有种豁然开朗的感觉。在此做一个小结。
1. 一些基本概念
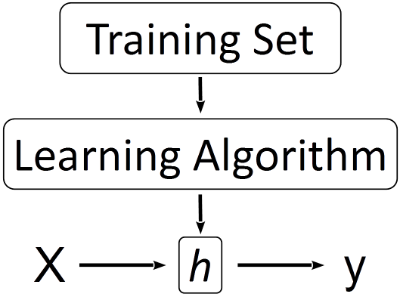
图1. 机器学习的基本过程
图1展示了机器学习的基本过程。对于学过高中数学的人来说,解方程是我们再熟悉不过的事情了。例如一个二元一次方程组,其解(如果存在的话)就是平面上两条直线的交点,此时方程以及参数(方程的系数)都是确定的。我们通常意义上的算法相当于一个定义好的函数(图1中的$h$),应用该算法的过程就是带入不同的自变量求函数值的过程。然而在机器学习算法中,最大的不同在于没有一个"定义好的函数",而是需要通过收集到的数据训练出一个函数(图1中从Training Set到$h$的过程),本质上是对训练集中数据的一种概括和总结。例如只有两个参数的线性回归就是在二维平面上找一条适合描述训练集中样本点变化规律的直线的过程。
传统的确定性算法与机器学习算法的区别可以用下图表示:

图2:传统编程与机器学习之间的差别,
如果将一个程序大致分为三个部分:输入、输出和算法,那么传统编程中已知的是输入和算法,需要求输出;机器学习中则是已知输入和输出,需要通过训练(学习)来得到有泛化能力的算法。
开普勒通过分析第谷留下的大约20年的天文观测数据,建立的开普勒三大定律;孟德尔通过分析他自己在豌豆实验中获得的不同性状数据,建立了孟德尔遗传定律。这两位科学家所做的事情,其本质也是对实验数据的概括、总结,最终提炼出了具有高度概括和普适价值的基本定律。这样想想,机器学习算法确实有了几分智能的味道。
- 训练集(Training Set):为了研究一个变量(x)与另一个变量(y)的关系,而通过观察、测量等方式获得的一组数据。这组数据中收集了x和与之对应的y——一个数据对(x, y)。例如我们要研究房屋面积(x)和售价(y)之间的关系,每观察一套已出售的房屋,就得到一个数据对(x, y)。观察10套已出售的房屋,就可以得到10个这样的数据对,这时就得到了一个用来研究房屋面积和售价之间的关系的训练集了(虽然样本量比较小)。这些数据集一般采集自现实环境中,属于现象(我们的目的是透过现象看本质)。
- 样本(Sample):训练集中采集数据的对象就是一个样本,例如一套已出售的房屋。
- 模型(Model):由于某些历史原因,机器学习中的模型也被叫做假设(hypothesis, h),这个h就是我们透过现象想要寻找的"本质"。建立模型的过程通常就是确定一个函数表达式的过程(是否还记得寒假作业中的这类题目:观察一组数,写出下一个数是什么?)。最常见的模型是回归模型(线性回归或逻辑回归等),例如我们假设房屋面积与售价之间的关系是一个线性回归模型,则可以写成:$$h(\theta) = \theta_0 + \theta_1 x \qquad \ldots (1)$$ 其中h是函数(可能更习惯叫做y,但在机器学习中y一般表示已知的函数值,即后面的因变量;这里的h相当于预测得到的y),θ是函数的参数(也可以看做是每个自变量的权重,权重越大,对y的影响也越大),x是自变量。
- 训练模型(Training Model):选定模型(选择合适的模型需要丰富的经验)后,函数的一般形式就确定了。通常所说的训练模型是指利用训练集求解函数的待定参数的过程。上面的(1)式与直线方程的一般形式y = ax + b是相同的,这里不过换了一种写法。此时我们知道模型是一条直线,为了确定这条直线的确定方程,我们需要求出两个未知的参数——θ0(截距)和θ1(斜率),如果训练集中只有两个样本,那就只是求一个二元二次方程组就解决问题了。
- 特征(Feature):特征就是在一个模型中,所有想研究的自变量(x)的集合。例如我们在研究房屋售价的模型中,所有可能影响售价的因素都可以看成是一个特征,房屋面积、所在城市、房间个数等。在建立模型的过程中,特征的选择是一个大学问,甚至有专门的分支来研究特征选择或特征表示。
2. 训练集的表示
上面提到过,训练集就是许多的(x, y)数据对的集合。其中x是因变量,y是自变量。通常认为x的变化引起了y的改变,即x的值决定了y的值。在预测房屋价格的模型中,假如我们能找到所有影响房屋价格的因素(所有的x),并且确定各个因素准确的参数(θ),那么理论上可以准确的预测出任何房屋的价格(y)。
2.1 单因素训练集中自变量的表示方法
- 单因素相当于方程中只有一个自变量,这个自变量可以用一个小写字母x来表示;
- 如果收集了多个样本,则通过在右上角添加带括号的角标的方式区分,表示为x(1), x(2), ..., x(m),其中m表示样本的个数;
- 矩阵的表示:向量一般用小写字母表示,矩阵用大写字母表示。所有单因素样本中的x可以用一个m x 1(m行1列)的列向量x(小写字母)(只有一列的矩阵就是一个列向量)来表示:$$x = \begin{pmatrix} x^{(1)} \\ x^{(2)} \\ \vdots \\ x^{(m)} \end{pmatrix}$$
2.2 多因素训练集中自变量的表示方法
- 多因素相当于方程中有多个自变量(多个feature),不同的自变量之间使用右下角添加不带括号的角标来区分,表示为x1, x2, ..., xn,其中n表示feature的个数;
- 当存在多个样本时,可以用一个m x n(m行n列)的矩阵X(大写字母)来表示:$$X = \begin{bmatrix} x_{1}^{(1)} & x_{2}^{(1)} & \ldots & x_{n}^{(1)}\\ x_{1}^{(2)} & x_{2}^{(2)} & \ldots & x_{n}^{(2)}\\ \vdots & \vdots & \ddots & \vdots \\ x_{1}^{(m)} & x_{2}^{(m)} & \ldots & x_{n}^{(m)} \end{bmatrix}$$
2.3 训练集中因变量的表示方法
无论是单因素还是多因素,每一个样本中都只包含一个因变量(y),因此只需要区分不同样本间的y,y(1), y(2), ..., y(m),其中m表示样本的个数;
用列向量y表示为:$$y = \begin{pmatrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(m)} \end{pmatrix}$$
3. 参数的表示
也许是某种约定,在机器学习中,一般都是用θ来表示参数,参数是自变量X的参数(也可以看做是每个自变量的权重,权重越大的自变量对y的影响也越大),理论上,有多少个自变量就有多少个参数,但就像在直线方程y = ax + b中表现出来的那样,除了x的参数a,还有一个常数项b。因此参数一般比自变量的个数多一个,当有n个自变量的时候,会有n+1个参数。
最终的模型是由一个特定的方程来表示的,方程中的未知参数,是在训练模型的过程中确定的。这些参数对于所有的样本都是相同的,例如第一个样本x(1)中的第一个自变量x1的参数与任意其他样本x(i)中第一个自变量x1的参数是相同的。因此不用区分样本间的参数,只用区分不同自变量之间的参数,可以使用一个n+1维的列向量θ来表示所有的参数:
$$\theta = \begin{pmatrix} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{pmatrix}$$
4. 模型的表示
这里说的模型就是一个特定的函数,上面已经提过,模型一般使用h来表示。下面用线性回归模型来举例说明模型的符号表示。
4.1 直接表示
直接表示方法是我们在没有学习线性代数之前的代数表示方式。
- 单变量线性回归方程:$$h_\theta (x) = \theta_0 + \theta_1 x$$
- 多变量线性回归方程:$$h_\theta (x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_3 + \ldots + \theta_n x_n$$
4.2 矩阵表示
学习了线性代数后,可以使用矩阵来表示上面的方程,不仅表示起来方便,直接进行矩阵运算效率也更高效。在这里需要特别说明的一点是,为了配合矩阵的表示,在上面的方程中添加了x0,并且x0=1,且将θ0作为x0的参数。
- 单变量/多变量线性回归方程:$$h_\theta (x) = X \theta = \begin{bmatrix} x_{0}^{(1)} & x_{1}^{(1)} & \ldots & x_{n}^{(1)}\\ x_{0}^{(2)} & x_{1}^{(2)} & \ldots & x_{n}^{(2)}\\ \vdots & \vdots & \ddots & \vdots \\ x_{0}^{(m)} & x_{1}^{(m)} & \ldots & x_{n}^{(m)} \end{bmatrix} \begin{bmatrix} \theta_0 \\ \theta_1 \\ \vdots \\ \theta_n \end{bmatrix}$$,此时X是一个m x (n+1)的矩阵,每一行表示一个样本,每一列表示一个特征,结果是一个m x 1的列向量,其中m表示样本的个数,n表示变量的个数(X中的每一列具有同样的参数,一列表示在不同的样本中同一个特征的取值);
- 当只有一个样本多个变量时,还可以表示为:$$h_\theta (x) = \theta^T x = \begin{bmatrix} \theta_0 & \theta_1 & \ldots & \theta_n \end{bmatrix} \begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_n \end{bmatrix}$$,此时x是一个(n+1)维的列向量,每一行表示一个变量的值。
Reference
https://www.coursera.org/learn/machine-learning
http://blog.sciencenet.cn/blog-100379-1037923.html
https://www.sumologic.com/blog/devops/machine-learning-deep-learning/